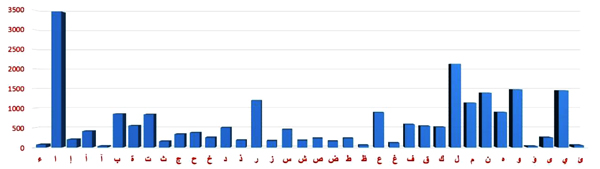
Fig. (11)
Distribution of the number of samples per character in the segmented Arabic characters dataset.